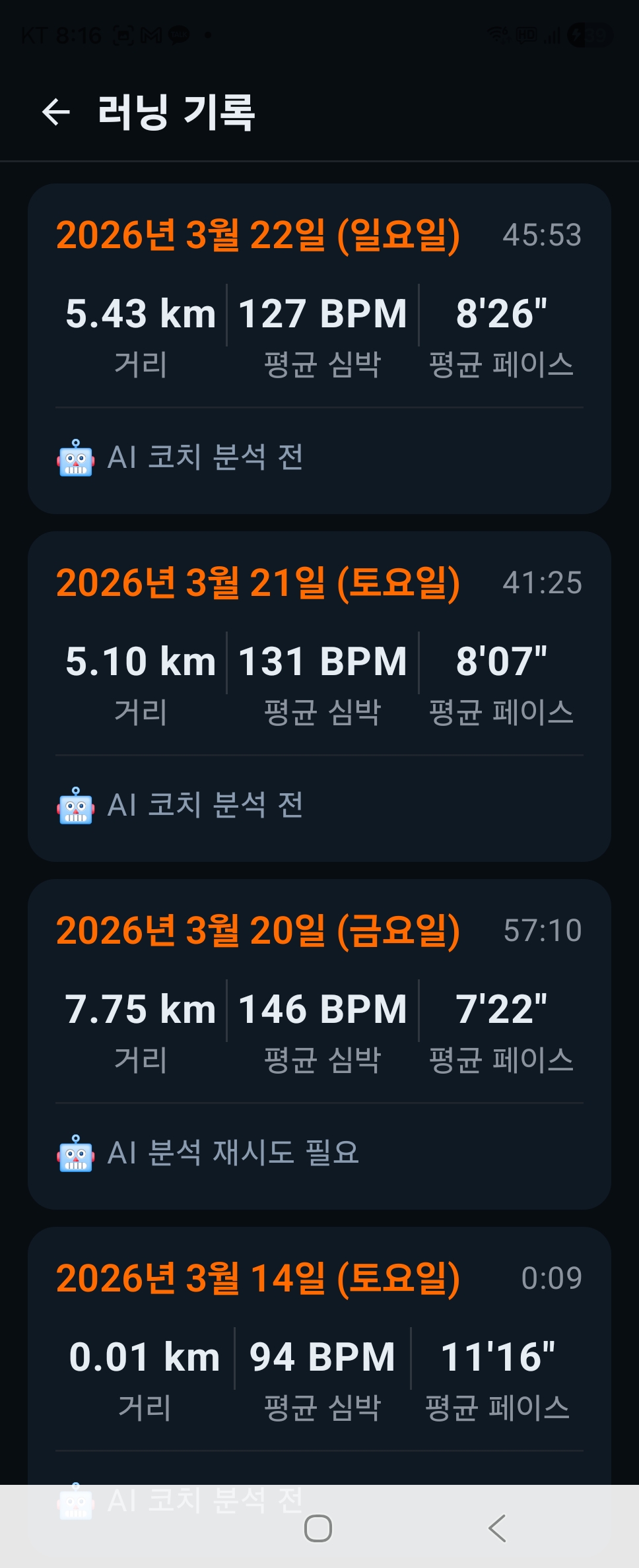
The App Was Done. But I Couldn't Trust the Data.
Today I ran 5.43km in 45 minutes and 53 seconds.
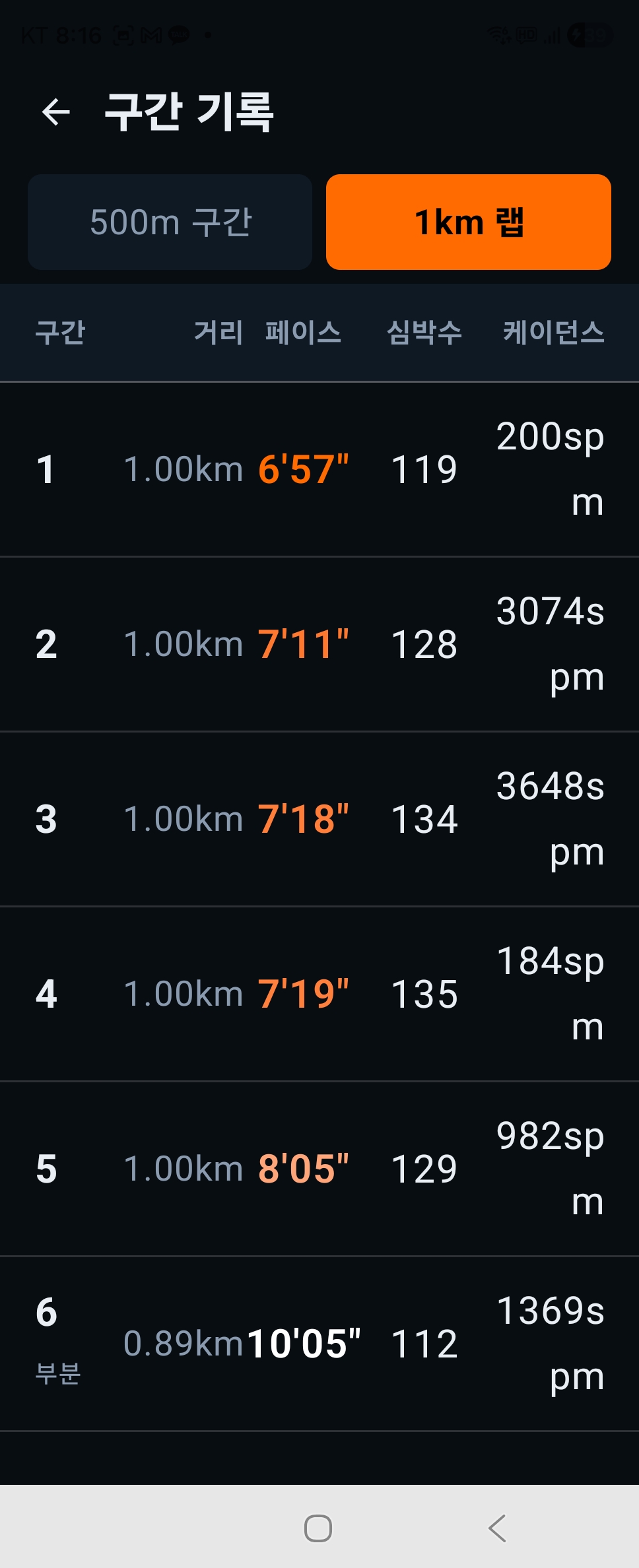
Average pace: 8’26”. Heart rate: 127 BPM. On paper, a decent run. But when I opened the split data, the cadence looked like this:
Segment 1: 200 spm. Segment 2: 3,074 spm. Segment 3: 3,648 spm.
No human takes 3,000 steps per minute. I knew right then — this app couldn’t be trusted.

I can’t read code. I can’t find the problem myself.
So I started with Meta-chulbuji. “The split cadence is way off. What do you think might be wrong?” Meta-chulbuji mapped out the possible causes. Armed with that, I asked Claude to run a diagnosis. Claude identified the structural issues, and I turned those findings into a brief — then handed it to Claude Code. Claude Code made the actual fixes.
My job was to judge and connect in between.
And it wasn’t just cadence. Pace was jumping between 3 and 14 min/km. Distance was skipping in 400m chunks. The watch and GPS were pulling in opposite directions and colliding. Five separate problems — each diagnosed separately, each handled separately. Not “fix everything.” One cause at a time. One fix at a time.
Verification still remains.
The fixes are in. But with a running app, you only know if it worked when you run. If the next time I open my split data and the cadence is quietly sitting somewhere between 160 and 180 spm — that’s when I can say it’s fixed.
Today wasn’t a day for adding features. It was the day a person who can’t read code, working with multiple AIs across clear steps, rebuilt the foundation for data worth trusting. The coaching comes after that.
Curious whether my cadence comes back to normal on the next run?
What I did: Fixed 5 data bugs by collaborating with multiple AIs — step by step. What broke: Cadence hit 3,648 spm. Pace swung between 3 and 14 min/km. What I learned: I don’t read code. I direct AI. That’s the workflow.